
周海波,李 天
(西华师范大学 电子信息学院,四川 南充 637009)
近年来,由于网络社交媒体的普及,人们在社交媒体上进行聊天评论的活动更为频繁。不同于日常的交流,网友在社交媒体上的评论往往更倾向于利用反讽、讽刺(以下将这一语言现象统称为讽刺)等隐喻方式表达自己的观点和看法。虽然传统的自然语言处理方法对于直抒胸臆的表达方式的情感分类和文本分类的精确率已经达到了一个较高的水平,但对于讽刺这一类隐喻表达方式的情感分类精确率依然不高。而人工审查的方式费时费力,需要较高的时间和经济成本。本文在调查了现有的相关文本分类技术和情感分类技术后提出了一种BERTCNN 中间任务转移模型对目标文本进行讽刺识别分类。本文针对目标任务特点进一步改进了BERT模型,首先对相关的中间任务进行微调,再对目标任务生成文本向量。另外,基于讽刺(隐含的消极)和情绪之间的相关性,本文探索了一个迁移学习框架,将情绪分类作为中间任务,将知识注入到讽刺检测的目标任务中,再结合CNN 卷积网络对文本特征进一步提取,最后通过Softmax 函数完成分类。实验证明,本文提出的模型在此任务上的性能好于以往的大多数模型。
BERT(Bidirectional Encoder Representations from Transformers)是一种用于自然语言处理任务的预训练模型,由Google 在2018 年发布[1]。BERT 通过预先训练来捕获句子中语义和语法结构之间的关系,这种预训练可以被用于各种自然语言处理任务,如语言推理、问答和文本分类。在文本分类中,BERT 通过在预训练阶段学习语义和语法结构的关系,然后在训练阶段通过这些知识来对文本进行分类。
BERT 的模型结构使用了Transformer 模型的编码部分,由12 层Transformer 叠加而成。模型的输入由3 种嵌入层累加构成,分别为:
(1)词嵌入(token embeddings),将每个词转换成固定维度的向量;
(2)分段嵌入(segment embeddings),用于区分不同的句子;
(3)位置嵌入(position embeddings),用于表征词语位置关系。
原理如图1 所示。
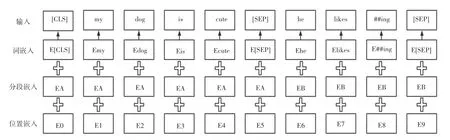
图1 BERT 原理图Fig.1 BERT schematic diagram
BERT 处理下游任务如文本分类任务一般采用微调(fine-tune)的方式,这种方式只需要少量的原模型参数调整。
同样,也可以将BERT 预训练模型生成的文本向量作为输入输出到其他模型中,如在BERT+CNN模型中,文本会先经过BERT 模型进行预处理,然后将输出的文本向量作为CNN 模型的输入;
在CNN模型中,文本向量会经过卷积层和池化层,捕获文本中的特征;
最后将捕获的特征和BERT 模型的输出结合在一起,输入到全连接层进行分类。
CNN(Convolutional Neural Network)最开始是一种用于图像处理的神经网络模型,同样也可以用来处理文本数据[2]。在文本分类中,CNN 通过使用卷积层来捕获文本中的特征,然后通过全连接层将捕获的特征进行分类。
CNN 模型的网络结构主要包括3 个部分:输入层、卷积层和池化层。
(1)输入层:将文本转换成向量的形式作为模型的输入;
(2)卷积层:使用卷积核在输入矩阵上进行卷积操作,捕获文本中的特征,卷积核是一个矩阵,其会在输入矩阵上进行移动并与输入矩阵进行卷积操作;
(3)池化层:使用池化操作来减少卷积层输出矩阵的维度,池化操作会在输出矩阵上进行滑动,并选择最大值或平均值作为新矩阵的值。
最后,通过连接全连接层,将捕获的特征输入到输出层进行分类,原理如图2 所示。

图2 CNN 文本分类原理图Fig.2 Schematic diagram of CNN text classification
迁移学习(Transfer Learning)指在解决一个新的问题之前,先使用已经解决过类似问题的模型来解决新问题,这样可以减少训练数据的需求,并提高模型的训练效率和性能[3]。迁移学习常用于自然语言处理、计算机视觉等领域,可以帮助在缺少大量数据的情况下提高模型的性能。
基于BERT 的文本分类工作就可以视为一种迁移学习的方式,即通过已有的通过大量文本训练的BERT 模型结合目标任务做参数微调,这种微调不会花费太多算力和时间。而迁移学习在目标任务的数据量不足的情况下可以采取训练与目标任务相关的中间任务做参数微调的方式以达到更好的分类效果。
提高BERT 预训练模型下游文本分类任务的精确性有两种方法:
(1)将BERT 预训练模型再训练;
(2)使用迁移学习的方法针对目标任务进行中间任务训练微调。
第一种方法模型在性能上可能有较大精度的提升,但这是一个费时费力的过程,这种方法往往需要大量的运算资源和大量的数据集,适用于专业领域极强的文本分类,如出现专业术语较多的文本分类上[4]。
本文从语法上讲讽刺文本识别的分类应该与文本情绪分类有一定的联系[5]。已有文献证明对于BERT 预训练模型进行相关中间任务的训练可以有效微调BERT 预训练模型[6]。故本文采取迁移学习训练中间任务的方式对BERT 预训练模型进行微调,以达到预训练模型更适合于讽刺文本分类的目的,本文使用迁移学习训练中间任务的模型图如图3 所示。

图3 迁移学习训练中间任务的模型图Fig.3 Model diagram of transfer learning training intermediate task
完成BERT 模型对中间任务数据集的情绪分类训练之后,本文利用完成了中间任务训练进行权重参数微调后的BERT 模型将目标文本向量化,由于目标文本为短文本数据集,数据多以字符数小于25的文本为主。卷积神经网络(CNN)对短文本的分类有较好效果[7],故本文提出融合卷积神经网络(CNN)对BERT 进行扩展,以提取更准确的特征向量,流程图如图4 所示。

图4 融合卷积神经网络(CNN)对BERT 扩展流程图Fig.4 Flow chart of extending BERT by fusing convolution neural network(CNN)
本文提出的BERT-CNN 中间任务转移模型的网络结构模型如图5 所示,使用了3 个卷积通道尺寸分别为2×768,3×768,4×768 的卷积核,通过卷积核的文本向量进行ReLu 激活函数操作以防止梯度爆炸并加快网络的训练速度,Relu 操作后进行文本向量的特征融合,特征融合之后的文本向量由全连接层连接Softmax 激活函数进行分类。

图5 BERT-CNN 中间任务转移模型Fig.5 BERT-CNN Intermediate task transfer model
目前开源数据集平台中,尚且缺少完整规模较高质量的简体中文讽刺文本识别的文本数据集,故本文采用github 上开源的英文数据集SemEval2018-Task3。该数据集的文本数据来源于Twitter 社交媒体,由1 286 条评论组成,其中612 条讽刺评论,674条非讽刺评论。数据大多为社交媒体平台上字符数小于25 的短文本网络评论,标注方法为众包由多人标注完成。数据集分为两个子任务数据集,第一个子任务为粗粒度的讽刺识别任务,即仅对文本是否为讽刺文本进行分类;
第二个子任务为细粒度的讽刺识别任务即在第一个子任务的基础上将讽刺细分为3 类讽刺类型。本文使用的是第一个子任务,仅做文本是否属于讽刺文本的分类。
迁移学习中中间任务学习的数据集本文采用EmoNet 数据集,该数据集的文本数据来源于Twitter社交媒体,是一个情感分类的数据集,有两种标签:negative(消极)和positive(积极),分别使用0,1 表示。
由于使用数据集为英文文本数据集,故不需要分词等一般操作,基于此类文本的特殊性做数据预处理:
(1)Twitter 评论文本中往往存在一些网络链接等,对讽刺识别任务没有帮助,故将此类链接全部删除;
(2)Emoji 表情、标点符号等非文本部分对讽刺识别存在帮助,故将其保留并转换为文本形式;
(3)某些类似错误单词等非法词汇会极大的增加网络训练的词汇量,且这类词汇往往对训练无法提供有效帮助,故对数据集中出现次数没有超过5次的无效词汇进行删除操作。
实验在PyTorch 深度学习框架下使用Hugging Face 库中的对应函数构建目标模型,Hugging Face 是一个开源的机器学习模型库,其中包含大量训练好的机器学习模型。具体实验环境配置见表1。

表1 环境配置Tab.1 Environment configuration
BERT 模型采用的是由谷歌提供的开源BERT预训练模型BERT-Base,Cased:12-layer,768-hidden,12-heads,110M parameters,具体参数见表2。

表2 BERT 模型参数设置表Tab.2 Model parameter setting table
卷积神经网络CNN 的参数情况见表3。

表3 CNN 卷积网络的参数情况表Tab.3 CNN Model parameter setting table
本文使用F1值和准确率作为本文模型实验的评价指标,公式(1)~公式(4)。
精确率:
召回率:
准确率:
F1值:
其中,TP为预测为正,实际为正;
FP为预测为正,实际为负;
TN为预测为负,实际为负;
FN为预测为负,实际为负。
为了验证本文提出方法的分类效果,本文与一般常用文本分类模型SVM、TextCNN、LSTM 进行了对比实验,模型使用的是Hugging Face 库中的对应模型,文本向量由Word2vec 预训练模型方法生成,训练时均采取不更新预训练模型参数的方式进行,实验结果见表4。

表4 与常用模型对比实验结果Tab.4 Comparison of experimental results with common models%
为了验证中间任务学习和融合模型的效果提升,本文还设计了以下实验,将本文提出的模型BERT(有中间任务训练)+CNN 与BERT(无中间任务训练)、BERT(有中间任务训练)和BERT(无中间任务训练)+CNN 模型进行对比实验,实验结果见表5。
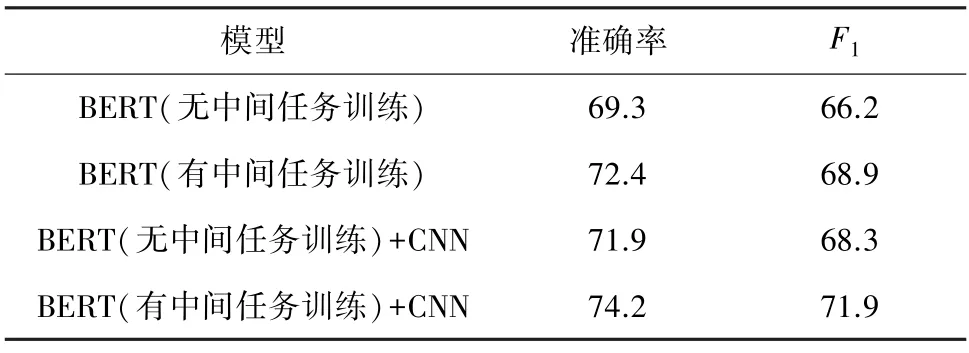
表5 验证中间任务学习和融合模型的效果实验结果Tab.5 Validate the effect of intermediate task learning and fusion model%
由表4 和表5 实验结果可以看出,BERT 预训练模型对文本数据集的分类效果更好;
而进行了中间任务训练的BERT 模型的使用效果要优于直接使用BERT 模型;
BERT 和CNN 的融合模型效果也优于直接使用BERT 模型进行分类,说明BERT-CNN中间任务转移模型对比常规模型具有更好的性能优势。
本文针对短文本讽刺文本分类的特点提出了一种基于BERT-CNN 中间任务转移模型,实验证明该模型在短文本讽刺文本数据集上相较其他常见模型具有更好的性能。现在的短文本讽刺文本的文本识别分类依然存在一些问题,比如缺少简体中文类讽刺文本数据集,文本数据集缺少更多辅助信息等,在后续的研究中将针对这些问题展开进一步工作。
猜你喜欢短文卷积向量向量的分解新高考·高一数学(2022年3期)2022-04-28基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02聚焦“向量与三角”创新题中学生数理化(高中版.高考数学)(2021年1期)2021-03-19从滤波器理解卷积电子制作(2019年11期)2019-07-04KEYS时代英语·高二(2018年7期)2018-12-03Keys时代英语·高二(2018年3期)2018-06-06基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23一种基于卷积神经网络的性别识别方法电视技术(2014年19期)2014-03-11版权所有:上派范文网 2010-2024 未经授权禁止复制或建立镜像[上派范文网]所有资源完全免费共享
Powered by 上派范文网 © All Rights Reserved.。沪ICP备12033476号-1